
One of the great promises of using Kubernetes is the ability to scale infrastructure dynamically, based on user requirements (In our Introduction we have already gone into this). However, by default, Kubernetes does not automatically add or remove instances. To do this, the Kubernetes Cluster Autoscaler and the Pod Autoscaler be activated as extensions. We will explain how this works and what forms of scaling there are within clusters in the following sections:
- Basics
- Scaling Layers: Pod Layer & Cluster Layer Scaling
- What are resource requests?
- Resource requirements and limitations
- Autoscaling features in Kubernetes
- Kubernetes autoscaling in practice
The first part of the article covers important basics about Kubernetes autoscaling: levels of scaling, as well as resource requests, requirements and limits. We then go into detail about the individual autoscaling tools or add-ons for Kubernetes (HPA, VPA, and Cluster Autoscaler). The third part is then a short summary with recommendations for the practical use of autoscaling in Kubernetes.
1. basics
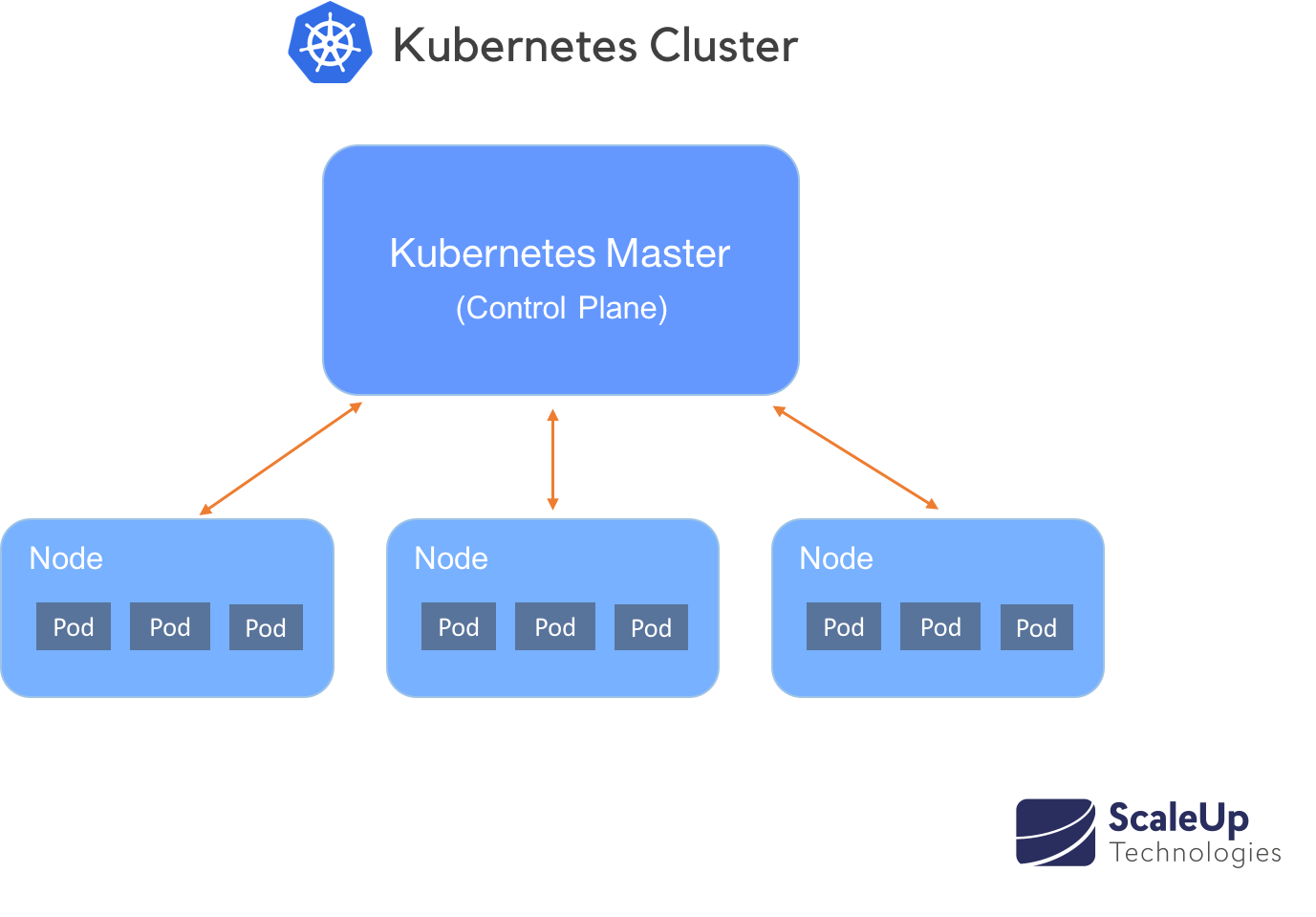
Clusters are the way Kubernetes arranges machines into groups. Clusters consist of nodes (individual machines, usually virtual machines) running "pods". A pod in turn has containers that request resources such as CPU, memory, and GPU (read "The Architecture of Kubernetes").
Scaling Layers: Pod layer & cluster layer scaling
Effective Kubernetes scaling requires coordination between two levels of scaling, once at the pod level and once at the cluster level. The (1) Pod Layer Autoscaler allows scaling of available resources within containers in two directions, horizontally and vertically through the Horizontal Pod Autoscaler (HPA) and the Vertical Pod Autoscaler (VPA). The (2) Cluster Autoscaler (CA) on the other hand, increases or decreases the number of nodes within the cluster.
What are resource requests?
Short ReviewWe remember the Kube scheduler in the Control Plane. The Control Plane is the master node within the Kubernetes cluster. The Kube scheduler's job is to decide where to run a particular pod. Are there nodes with enough free resources to run the pod? To effectively schedule the execution of pods, the Kube scheduler needs to know the minimum and maximum allowable resource requirements for each pod. So it queries these minimum and maximum requirements before new pods can be executed accordingly.
Kubernetes knows two types of resources that are managed: CPU and memory (storage). There are other resource types that can cause conflicts within a Kubernetes cluster, such as network bandwidth, E /A operations, and memory, but Kubernetes cannot currently describe pod requirements for these. Since most pods do not require a full CPU, requirements and thresholds are usually specified in millicups (sometimes called millicores). Memory is measured in bytes.
There is also the ability to scale pods based on custom metrics, multiple metrics, or even based on external metrics (e.g., error frequencies within the app).
Resource requirements
A resource requirement specifies the minimum amount of resources required to run the pod. For example, a resource requirement of 200m (200 millicpus) and 500MB (500 MiB of memory) means that the pod cannot be scheduled on a node with less than the resources. If no node with sufficient capacity is available, the pod remains in a pending state until it becomes available again.
Resource limitations / resource limits
A resource limit specifies the maximum amount of resources that a pod can use. A pod that attempts to use more than the allocated CPU limit is automatically throttled, which reduces performance. A pod that attempts to use more than the allowed memory limit is terminated. If the terminated Pod can be reallocated at a later time because there are sufficient free resources on the same or another node, the Pod is restarted.
Important: Minimum requirements and resource limits can only be set at the container level and should be chosen wisely.
2. autoscaling features in Kubernetes.
At the container level, resources can be scaled in two directions: horizontally using the Horizontal Pod Autoscaler (HPA) and vertically using the Vertical Pod Autoscaler (VPA).
Horizontal Pod Autoscaling (HPA)
The Horizontal Pod Autoscaler (HPA) is already implemented as a Kubernetes API resource and controller. A Replication Controller manages a certain number of pod replicas (a so-called ReplicaSet).
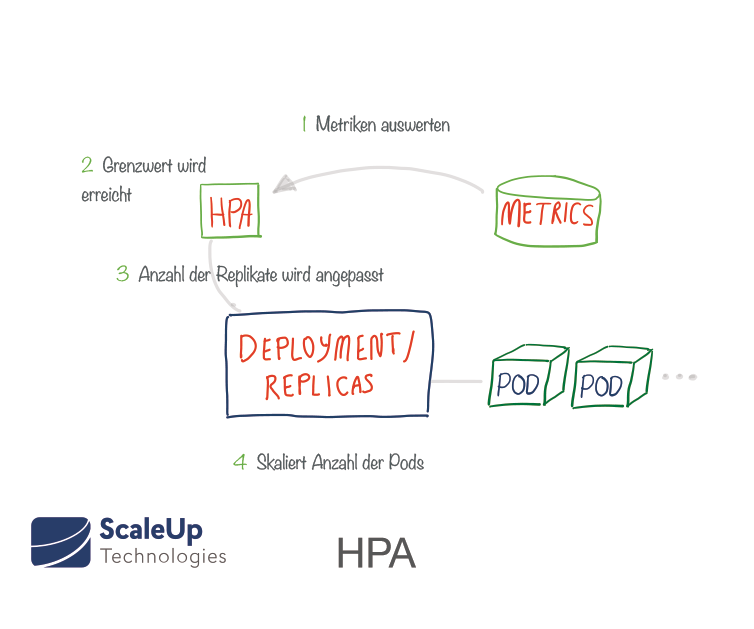
If a replica fails, another one is started to replace it. The creation of new pods is thereby mimicked that of replicas. The desired number of replicas is specified in the deployment manifest - at the deployment level. ReplicaSets allow pods to be grouped together and contain logic for scaling them and lifecycle defaults. Through the Horizontal Pod Autoscaler (HPA), Kubernetes can automatically adjust the number of replicas to meet specific requirements. To do this, the HPA monitors certain metrics to determine if the number of replicas needs to be increased or decreased. Most commonly, CPU and memory are used as trigger metrics. The measured resource status determines the behavior of the controller. The Replication Controller periodically adjusts the number of replicas to match the observed average CPU utilization to the target specified by the user, e.g., if a CPU utilization of 80% is targeted. If the average utilization of all existing pods in the deployment is only 70% of the requested amount, the HPA will reduce the size of the deployment by decreasing the target number of replicas. On the other hand, if the average CPU utilization is 90%, exceeding the target of 80%, then the HPA will add more replicas to lower the average CPU utilization.
Vertical Pod Autoscaling (VPA)
The Vertical Pod Autoscaler (VPA) is a relatively new Kubernetes add-on that works similarly to the HPA, but at the pod level. The VPA assigns more (or less) CPU / memory resource requirements to existing pods. It can thus assist in determining the ideal values for resource requirements.
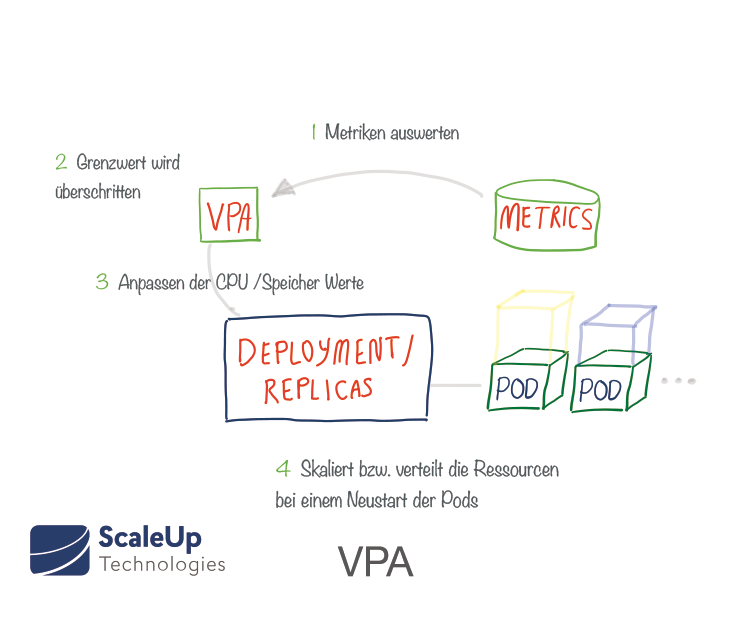
VPA monitors a given deployment and automatically adjusts the resource requirements for the pods to match the actual requirements in use. After the adjustment, the pods are restarted. In doing so, it ensures that the required minimum number of pods is always available. It is also possible to set the minimum and maximum resources that the VPA may allocate to each pod . There is also a test mode (VPA Recommender) for the VPA that makes suggestions for adjustments based on measured metrics and OOM events without actually modifying the running pods.
HPA and VPA are currently only compatible for custom metrics (not for CPU and Memory).
Cluster autoscaler
Cluster Autoscaler (CA) is enabled one node pool at a time. Cluster Autoscaler scales cluster nodes based on outstanding pods. At 10-second intervals, CA checks for pending pods, their resource requests, and checks if the cluster size needs to be increased. CA then communicates with the cloud provider to request additional nodes or unassign inactive nodes. The cluster autoscaler adds or removes additional nodes in a cluster based on resource requests from pods.
When auto-scaling is enabled and pending workloads are waiting for a node to become available, the system automatically adds new nodes to meet the demand.
However, Cluster Autoscaler does not take into account the resources actively used by pods, but assumes that the specified pod resource requirements are correct.
Conversely, when there is spare capacity, the autoscaler consolidates the pods on a smaller number of nodes and removes the unused nodes.
3. Kubernetes autoscaling in practice
When you create a pod, the Kube scheduler selects a node on which to run the pod. Each node has a maximum capacity for CPU and memory that it can allocate for pods. The scheduler ensures that for each resource type, the sum of the resource requirements of the scheduled containers is less than the capacity of the node. In doing so, the scheduler may refuse to place a pod on a node if the capacity check fails, even though the actual memory or CPU resource usage on nodes is very low. This protects against a resource shortage on a node when resource usage is volatile and may increase later, for example, during performance peaks.
Basically, service and resource availability must be weighed against performance aspects and, of course, costs when autoscaling. A good approach is to set the resource limits for a container slightly above the maximum it uses in normal operation. It is also worthwhile to regularly check the resource requirements and limits with regard to their actual use.
If you want to learn more about the practical use of Kubernetes and autoscaling, feel free to contact us. You can also use Kubernetes with us for 14 days. test, a of our workshops visit or talk to us about your individual requirements.


